


Google contre-attaque avec de nombreuses annonces IA

Vous êtes désormais 35 abonnés à la Veille IA ! Merci à vous 😊
Dans mon dernier post, j’ai annoncé que je parlerai des AI Wearables dans ma prochaine publication. Mais Google a décidé de faire de grandes annonces, et il fallait que je vous en parle !
Le lundi 13 mai 2024, OpenAI annonçait en grande pompe son nouveau modèle ultra-performant GPT4-o lors de sa conférence Spring Update. Voir mon post complet sur le sujet. Le lendemain, c’était au tour de Google de contre-attaquer avec de nombreuses annonces concernant l’IA.
Google met de l’IA partout
C’est dans son fief de Mountain View, dans la baie de San Francisco en Californie, que le mastodonte Google a tenu sa conférence annuelle Google I/O 2024. C’était un rendez-vous très attendu par tous les amateurs de technologies, notamment après les révélations de la veille par OpenAI, concurrent direct principal sur les sujets d’intelligence artificielle.
Cet événement était donc l’occasion pour Google de prouver au monde que ses équipes mettent le paquet pour compenser leur retard sur OpenAI en matière d’IA, mais aussi de se rattraper à la suite de son dernier bad buzz concernant la génération d’image dans son modèle principal d’IA, Gemini. Voir mon post sur ce bad buzz.
Au programme de la conférence : de nombreuses annonces concernant donc ce fameux modèle Gemini, mais aussi au sujet de plusieurs de ses produits phares (le moteur de recherche Google, Gmail, Google Workspace, Android…). Sundar Pichai, le patron de Google, l’annonce lui-même : tous les services de Google seront d’une manière ou d’une autre concernés par l’intelligence artificielle.
En bref : Google met de l’IA partout.

Les améliorations concernant Gemini
Gemini, c’est le modèle de langage (ou LLM pour Large Language Model) phare de Google, leur concurrent au modèle GPT d’OpenAI. Tout comme GPT se décline en plusieurs versions comme GPT-4, GPT-4 Turbo ou la toute dernière version GPT-4o, Gemini se décline en plusieurs versions :
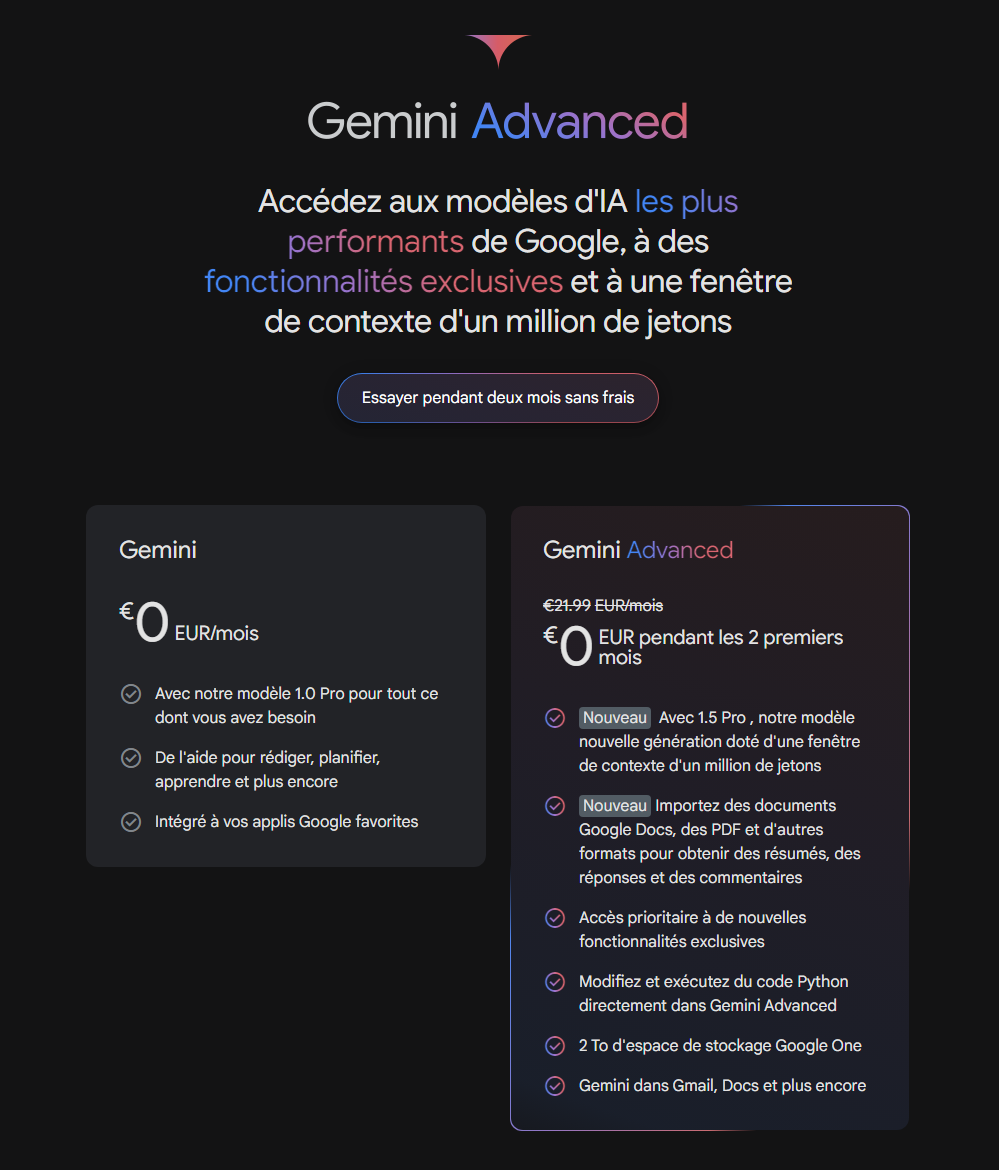
Gemini 1.5 Pro : le meilleur modèle chez Google, avec la meilleure performance pour une large variété de tâches. Existant depuis février 2024, Google a annoncé que c’est ce tout dernier modèle qui est désormais disponible dans la version payante de son chatbot Gemini Advanced. Ce chatbot est un concurrent direct de ChatGPT (OpenAI) ou de Copilot (Microsoft).
Gemini 1.5 Flash : annoncée pendant l'événement, cette nouvelle version du LLM optimisée pour la rapidité et l’efficacité d’exécution est spécialement conçue pour les tâches nécessitant une latence réduite.
Gemini 1.0 Ultra et Gemini 1.0 Nano sont d’autres versions, respectivement dédiées aux tâches complexes et aux tâches rapides. Toujours basées sur le modèle 1.0, elles sont donc bien moins performantes que les nouvelles versions 1.5 et devraient logiquement être supprimées ou remplacées prochainement.
Gemini 1.5 est un modèle multimodal, c’est-à-dire qu’il peut interpréter et générer à la fois du texte (y compris du code informatique), des images, de l’audio et même désormais d’interpréter des vidéos. Google a toujours mis l’accent sur sa fenêtre contextuelle (ou context window en anglais) importante par rapport aux modèles concurrents, c’est-à-dire sa capacité à traiter un plus grand nombre de tokens (voir mon post sur la tokenization).
En effet, Gemini 1.5 peut maintenant traiter plus de 2 millions de tokens, que ce soit en version Pro ou Flash. Selon Google, cela représente plus de 1,4 millions de mots, 22 heures d’audio ou 2 heures de vidéo. C’est beaucoup plus que la fenêtre contextuelle de GPT-4 Turbo ou même de GPT-4o qui peuvent eux ne traiter “que” jusqu’à 128,000 tokens.

Cependant, cette supériorité apparente de Gemini 1.5 doit être relativisée : pouvoir traiter plus de tokens ne signifie pas une meilleure performance. Chez OpenAI par exemple, les ingénieurs cherchent à compresser au maximum le nombre de tokens utilisés dans une tâche à des fins d’optimisation des performances. Nous l’avons vu dans mon précédent post, GPT-4o permet ainsi de traiter plus de contenu avec moins de tokens.
Au-delà de cette fenêtre contextuelle plus importante, Google a également annoncé une série d’améliorations dans plusieurs domaines sur Gemini 1.5 : une meilleure capacité de raisonnement, pour générer du code informatique ou encore pour traduire d’une langue à l’autre.
Gemini 1.5 Pro est d’ores et déjà accessible aux abonnés Gemini Advanced, même en France. Les utilisateurs de la version gratuite n’ont, pour le moment, accès qu’à l’ancienne version 1.0 Pro. En ce moment, les deux premiers mois sont gratuits !
Pour essayer Gemini gratuitement, ça se passe par ici : gemini.google.com
Gemini vs GPT
Lors de ma présentation de GPT-4o, je vous expliquais que le modèle était loin devant les autres au classement de la Chatbot Arena de LMSYS. Cette plateforme est une sorte d’arène qui permet d’envoyer le même prompt à deux modèles différents. L’utilisateur vote ensuite pour le modèle qui a répondu avec la meilleure réponse. Les modèles sont choisis à l’aveugle de sorte que l’utilisateur ne sait pas quel modèle a répondu quelle réponse. Un score ELO (inspiré du classement ELO des échecs) est enfin attribué à chaque modèle en fonction du nombre de “battles” remportées. Le classement qui en suit est considéré comme l’une des façons les plus objectives de comparer les performances entre plusieurs modèles de langage.
Voici l’état actuel du classement au 20/05/2024 :

GPT-4o, le dernier modèle d’OpenAI, reste pour le moment considéré comme le plus globalement performant de tous les LLM accessibles au public.
Gemini par-ci, Gemini par-là
Gemini n’est pas seulement un LLM permettant d’alimenter un chatbot à la manière de ChatGPT, c’est aussi un modèle qui va venir progressivement enrichir toutes les apps Google. Ainsi, Gemini permettra de résumer des e-mails dans Gmail ou des réunions dans Google Meet, mais viendra également améliorer la recherche d’images dans Google Photos.
Au-delà de ces applications bien connues de la suite Google, la firme a aussi annoncé la création d’un nouveau produit expérimental utilisant le LLM Gemini 1.5 : NotebookLM. Il s’agit d’une solution d’assistant virtuel permettant “d’optimiser votre réflexion” : vous importez les documents que vous souhaitez et, peu importe le sujet, votre assistant virtuel en devient instantanément un expert. Vous pouvez alors lire, prendre des notes et collaborer avec lui pour “affiner vos idées et mieux les organiser”.
Pour le moment, aucun des mastodontes de l’IA (OpenAI, Microsoft, Meta, Google etc.) n’a pu apporter de solution pratique, abordable et efficace pour répondre à ce besoin grandissant pour les particuliers et entreprises : pouvoir importer son propre jeu de données à un modèle de langage pour obtenir un assistant virtuel expert d’un besoin bien spécifique. Ce produit expérimental NotebookLM est donc un pas en avant intéressant dans cette direction. Pour le moment il n’est malheureusement que disponible aux Etats-Unis.
Parmi la myriade d’annonces réalisées pendant la conférence concernant de nouveaux produits ou des mises à jour de produits existants, on retrouve également :
La création de Véo, un outil d’IA générative permettant de créer ou de modifier des vidéos, pour concurrencer directement le modèle Sora d’OpenAI. Les deux produits concurrents ne sont pas encore accessibles au public.
La mise à jour Imagen 3, le modèle de génération d’images de Google. Cette nouvelle version rattrape un peu le retard pris sur le produit concurrent Midjourney : le modèle comprend mieux les prompts plus longs, permettant d’inclure plus de détails réalistes. Surtout, il permet de générer du texte lisible, ce qui a pendant longtemps été un challenge important pour les IA génératives d’images.
Deux nouveaux modèles dans la famille Gemma. Gemma, c’est une sélection de modèles ouverts légers “conçus à partir des mêmes recherches et technologies que celles utilisées pour créer les modèles Gemini”. Les deux nouveaux modèles sont PaliGemma, un modèle ouvert axé sur la vision et optimisé pour décrire des images, répondre à des questions sur des images etc ; et Gemma 2, une nouvelle génération du modèle Gemma avec 27 milliards de paramètres (rappelons que GPT-4 disposerait de plus d’un trillion de paramètres).
Music AI Sandbox, une suite d’outils musicaux permettant à n’importe qui de générer des sections instrumentales à partir de prompts. C’était le sujet du show d’introduction de la conférence avec une démo par le grand Marc Rebillet lui-même. Spoiler alert : ça n’a pas plus à tout le monde.
L’arrivée d’un nouveau TPU (Tensor Processing Unit) baptisé Trillium. Ici, on est sur une innovation matérielle plutôt que logicielle. Le sujet étant complexe, je ferai un post détaillé sur le sujet des TPU. Ce qu’il faut retenir, c’est que les TPU sont des sortes de processeurs créés par Google et optimisés pour réaliser les calculs dédiés à l’IA, et plus précisément les tâches liées au machine learning. Google a annoncé que son nouveau TPU Trillium est 4,7 fois plus performant que l’ancienne génération, et qu’il sera disponible aux clients de la Google Cloud Platform fin 2024. Cela permettra peut-être de convaincre les clients d’autres plateformes Cloud à rejoindre l’infrastructure Google, et de gagner de précieuses part de marché dans ce secteur ultra concurrentiel.
Mais l’annonce la plus importante de cette conférence Google I/O 2024 en matière d’IA est certainement celle du projet Astra.

Le projet Astra de Google : le futur de l’IA multimodale ?
Le projet Astra est la véritable réponse de Google face à OpenAI qui avait annoncé un produit similaire la veille : ChatGPT Voice. Le projet Astra est développé par DeepMind, le laboratoire principal de Google en matière IA et à l’origine de nombreuses innovations historiques dans le domaine.
Que ce soit pour ChatGPT Voice ou pour le projet Astra de Google, le concept est le même : un assistant vocal multimodal capable de répondre en temps réel à vos questions intégrant un élément visuel de l’environnement. L’expérience est beaucoup plus naturelle que dans les produits existants et ressemble plus à un appel en facetime avec un ami qui aurait la science infuse. Pointez un objet avec votre smartphone et demandez “qu’est-ce que c’est ?” pour obtenir une réponse en temps réel de l’assistant vocal. Vous pouvez l’interrompre et reformuler votre question ou demander des précisions de façon très naturelle, comme dans une conversation avec un humain.
Les produits sont tellement proches et la concurrence est si assumée que Michael Chang, l’un des directeurs du projet Astra chez DeepMind a réalisé sur Twitter la démonstration suivante : il a demandé à Gemini de décrire la vidéo de l’annonce de GPT-4o en utilisant l’assistant du projet Astra. Gemini transcrit en temps réel la conférence d’OpenAI, attribuant même les déclarations aux bons interlocuteurs.

Les produits sont tellement similaires que la seule vraie différence entre les deux démonstrations est que la voix de l’assistant vocal sur ChatGPT Voice semble beaucoup plus naturelle et humaine que celle du projet Astra, encore assez robotique très semblable à celle de l’actuel Google Assistant. Si certains ont été très séduits par la démonstration du projet Astra, d’autres y voient un énième signe que Google est à la traîne par rapport à OpenAI.
Faites vous une idée par vous même en comparant les deux démos (vous pouvez activer les sous titres en français si besoin) :
Démonstration de ChatGPT Voice :
Démonstration de Project Astra :
Si OpenAI semble pour le moment être en tête de la course à l’adoption du grand public avec son produit phare ChatGPT, il faut également se rappeler que le projet Astra n’est qu’un des innombrables projets en intelligence artificielle de Google. Il suffit de consulter le site Labs.google pour réaliser l’étendue des recherches réalisées en la matière par la firme de Mountain View. Si vous souhaitez en savoir plus sur les nombreuses annonces réalisées par Google pendant sa conférence, retrouvez leur communiqué de synthèse en anglais “100 choses que nous avons annoncées pendant Google I/O 2024”.
Dans mon prochain post, je vous parlerai des AI Wearables, ces accessoires à porter sur soi et qui embarquent l’intelligence artificielle pour nous assister au quotidien… ou pas ?